@파이토치로 딥러닝 제대로배우기 강의를 바탕으로https://itgo.kr/class/class_detail.asp?c_code=la_L110112
[ 데이터 ]
- 정형데이터의 열은 차원, 특성, 측정값
- 비정형데이터 : 자연어처리, 컴퓨터비전, 비디오데이터 등등
Pascal VOC
- 대표적인 Object Detection Dataset
- Classification Task : 각 이미지에 대한 label 예측
- Detection Task : Bounding Box와 label을 인식하는 Task
- Segmentation Task : 픽셀을 예측하는 Task. Object/class segmentation
COCO
- Large-scaled
CelebA
- 유명인사 얼굴 데이터 셋
- 활용 법 : BBOX labels, Landmarks(눈, 코, 입 등의 위치), attribute(얼굴 특징)
[환경]
딥러닝 프레임워크 : 딥러닝 쉽게 사용할 수 있도록 다양한 기능을 구현한 작성 규칙이 있는 라이브러리
(종류 - theano, TensorFlow, Keras, torch)
파이토치
- Torch 라이브러리를 기반으로 한 오픈소스 기계학습 프레임워크.
- GPU와 호환성이 뛰어남.
- Libraries : 연구 논문에서 다루는 다양한 데이터셋, 모델, Loss함수 등이 존재
Google Colab

[ 합성곱 신경망 CNN ]
- 시각 피질 구조(어떤 사물을 볼 때 어떻게 인식을 하는지. 어디에서 활성화 할지-Activation Function)를 모방하여 만든 Neural Network
- 입력 이미지로부터 특징을 추출하여 입력 이미지가 어떤 이미지인지 클래스를 분류함.
- convolution : 정보를 압축하여 획득하는 부분. k채널 - 정보량 많게
- pooling : 정보를 버리는 부분
- FEATURE LEARNING -> CLASSIFICATION

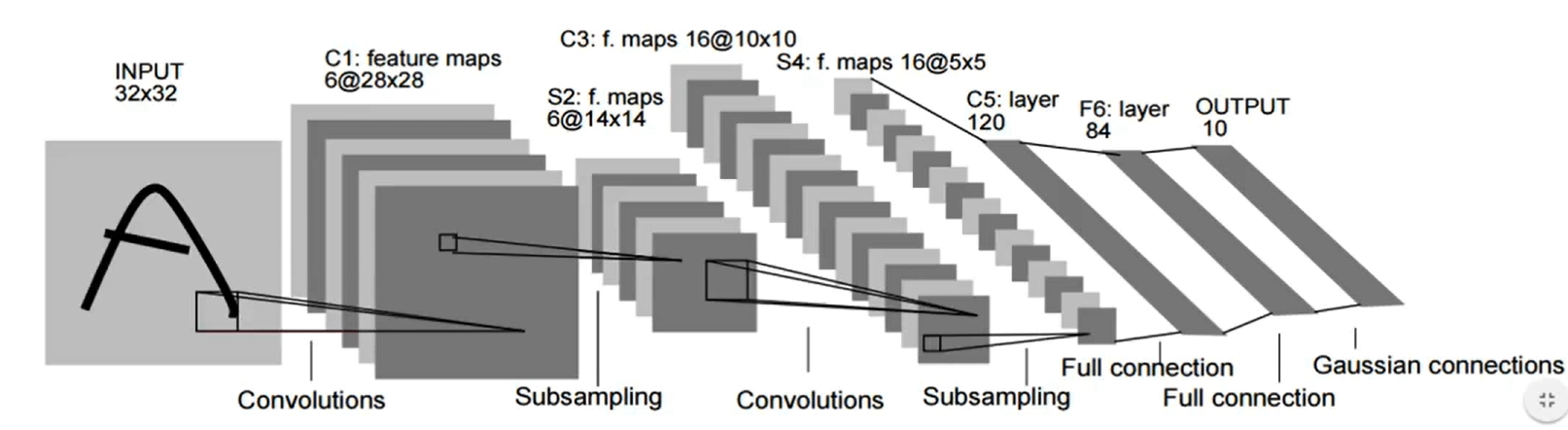
합성곱 신경망의 구조 및 특징
- 합성곱 신경망 = 합성곱 계층(뉴런을 활성화 시킴) + Pooling계층(정보를 버림)
- 필터와 스트라이드를 통해 Feature map을 추출
- feature learning(특징을 학습)에서는 입력으로 받은 데이터의 Grid를 줄여 나가면서 (채널을 늘려)정보량을 늘여나가고, classification 부분에서는 정보를 줄여나감으로써 최종 결과를 도출.
- Fully connected layer와 softmax layer을 통해 분류 등이 작업을 진행함.
- Channel은 한번에 연산이 됨(한번의 연산에서 모든 입력 이미지의 채널이 동시에 처리 됨)
Convolutional Layer
- 입력 데이터의 모든 픽셀에 연결하는 것이 아닌, 필터 안에 있는 픽셀만 연결
Pooling Layer
- 계산량과 메모리 사용량, 파라미터 수를 줄이기 위한 계층, 즉 Subsampling 수행
- 합성곱층과 마찬가지로 kernel_size, stride, padding 유형을 지정하지만 가중치는 없음
- 많은 정보 손실이 발생.
- Max Pool
- 필터가 매핑하고 있는 커널에서 가장 큰 값을 추출
- Average Pool
- 필터가 매핑하고 있는 커널의 평균값을 추출
- 정보손실이 적음. 연산비용이 많이 듦
- Global Pool
- 각 feature map에서 하나의 값만 출력
- 가장 정보 손실이 많음. 출력 층에 유용. 오버피팅 줄임. 전체 모델의 파라미터 줄임.

Stride
- Filter의 이동 거리를 의미
- 계산의 복잡도를 낮추기 위해서 사용됨.
- 데이터의 특징에 따라서 설정하는 것이 유리함.(예시) 시계열 데이터를 다룰 때 )
- 커지면 디테일 한 부분을 놓친다. ->파라미터가 줄어든다 ->정보손실이 커진다
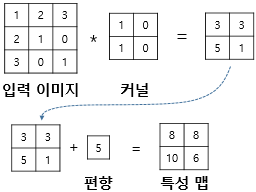
Filter (= kernel)
- 커널의 크기가 크면
- 압축이 많이됨. 한번에 관측하고자 하는 데이터가 많기 때문에 특징을 세부적으로 파악할 수 없음. 학습 파라미터 감소의 효과.
- 필터 사이즈로 어떤 출력물이 나오는지가 중요함.
Padding
- 원본 데이터 주변에 무의미한 값을 추가하여 filter를 투과하는 방법
- 일반적으로 주변에 0 을 넣음.
- 일반적으로 grid를 유지할 때 사용
Flatten
- 합성곱 신경망 학습을 하고 나면 행렬의 형태로 나타남. 이를 인공 신경망에 적용할 수 있도록 나열함.
Convolution Layer 생성
-인공지능 모델을 만드는 방법 : Functional API활용, Model class 상속, Using Sequential
방법1. Functional API
inputs = tf.keras.Input(shape=(32, 32, 3)) # 32x32x3 (RGB)
x = tf.keras.layers.Conv2D(filters=32,
kernel_size=(3, 3),
strides=(1, 1),
padding='valid',
activation='relu')(inputs)
x = tf.keras.layers.Conv2D(filters=64,
kernel_size=(3, 3),
strides=(1, 1),
padding='valid',
activation='relu')(x)
x = tf.keras.layers.Flatten()(x)
outputs = tf.keras.layers.Dense(10, activation=tf.nn.softmax)(x)
model_by_func = tf.keras.Model(inputs=inputs, outputs=outputs, name="model_by_func")
방법2. Model class 상속
class ModelByClass(tf.keras.Model):
def __init__(self):
super(ModelByClass, self).__init__()
self.conv2d_1 = tf.keras.layers.Conv2D(filters=32,
kernel_size=(3, 3),
strides=(1, 1),
padding='valid',
activation='relu')
self.conv2d_2 = tf.keras.layers.Conv2D(filters=64,
kernel_size=(3, 3),
strides=(1, 1),
padding='valid',
activation='relu')
self.flatten = tf.keras.layers.Flatten()
self.dense = tf.keras.layers.Dense(10, activation=tf.nn.softmax)
def call(self, inputs):
x = self.conv2d_1(inputs)
x = self.conv2d_2(x)
x = self.flatten(x)
return self.dense(x)
model_by_class = ModelByClass()
방법3. Using Sequential
model_by_seq = models.Sequential()
model_by_seq.add(layers.Conv2D(filters=32, kernel_size=(3, 3), activation='relu', input_shape=(32, 32, 3)))
model_by_seq.add(layers.Conv2D(64, (3, 3), activation='relu'))
model_by_seq.add(layers.Flatten())
model_by_seq.add(layers.Dense(10, activation=tf.nn.softmax))
모델 Compile
모델의 학습 방법과 평가 방법을 정의함. optimizer, loss, metrics 모두 여기서 선언함
model_by_func.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
모델 학습
aaa = model_by_func.fit(train_images, train_labels, epochs=10, validation_data=(test_images, test_labels))
'딥러닝(, 머신러닝)' 카테고리의 다른 글
| 2024.02.24 BITAmin동계플젝(YOLOv8, ResNet50) - DNN을 활용한 영화 인사이드 아웃 캐릭터 emotion 분석 (0) | 2024.02.27 |
|---|---|
| 컴퓨터 비전 기본 (1) | 2024.02.26 |
| LLM모델 (0) | 2024.02.09 |
| 경사하강법과 최적화 알고리즘 (2) | 2024.02.05 |
| 시계열 예측 모델, LSTM (1) | 2024.01.29 |


