@생성형 AI 활용방안 모색을 위한 사전 조사
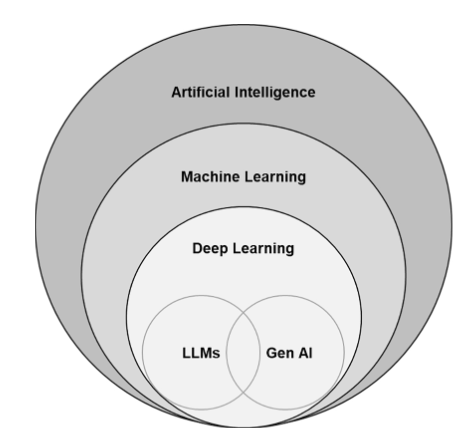
생성형 AI
방대한 양의 데이터를 학습하여 텍스트, 이미지, 오디오, 비디오 등 새로운 콘텐츠를 만들어내는 인공지능 기술.
(Chat GPT의 경우 대규모의 데이터를 학습한 언어 모델 기반의 서비스)
- 생성되는 콘텐츠의 종류에 따라 언어모델, 이미지모델, 비디오 모델로 분류됨.
- 멀티모달 : 텍스트와 이미지를 동시에 학습하는 모델. ->기초모델( Foundation Model )로 자리잡아가고 있음.
파운데이션 모델
텍스트, 이미지, 음성, 정형데이터, 3D시그널 등 구분하지 않고 학습에 이용.
파운데이션 모델이라는 용어는 연구자들이 광범위한 일반화된 데이터와 레이블이 지정되지 않은 데이터에 대해 훈련되고 언어 이해, 텍스트 및 이미지 생성, 자연어 대화와 같은 다양한 일반 작업을 수행할 수 있는 ML 모델을 설명하기 위해 만들어졌습니다.
- 작동 원리
- GAN, 트랜스포머, 변량 인코더 등 복잡한 신경망을 기반으로 함.
- 학습된 패턴과 관계를 사용하여 시퀀스의 다음 항목을 예측
- 더 선명, 명확한 이미지
- 문맥을 기반으로 텍스트 문자열의 다음 단계 예측
- 자체 지도학습을 사용하여 입력 데이터에서 레이블 생성. 즉, 훈련자 없음.
- 파운데이션 모델 예시 : BERT, GPT, Amaxon Titan, BLOOM 등
대규모 언어 모델 LLM
방대한 양의 데이터를 기반으로 사전 학습된 초대형 딥러닝 모델.
- 방대한 양의 데이터에 대해 사전학습 되며 파인튜닝 같은 기술 사용.
- LLM 학습 단계
- 데이터 수집 및 전처리
- 모델 선택 및 구성
- Google의 BERT 및 OpenAI의 GPT-3.5와 같은 대형 모델은 모두 트랜스포머 딥러닝 아키텍처를 사용.
- 트랜스포머 블록의 레이어 수, 어텐션 헤드수, 손실함수, 하이퍼파라미터같은 모델의 일부 핵심 요소를 트랜스포머 신경망 구성 때 지정해야함.
- 모델학습
- 지도학습 사용
- 학습 중 : 일련의 단어 제시, 해당 시퀀스의 다음 단어 예측. 예측과 실제 다음 단어 간의 차이를 기반으로 가중치 조정.
- 학습 시간을 줄이기 위해 모델 병렬화 기술 사용--> LLM을 처음부터 학습하려면 상당한 투자 필요.
- 대안 : 기존 언어 모델을 특정 사용 사례에 맞게 파인튜닝
- 평가 및 파인튜닝
- 성능 향상 법 : 하이퍼파라미터 조정, 아키텍처 병경, 추가 데이터 교육
- 파인튜닝 : PEFT방법(LLM에 소수의 새로운 매개변수를 추가하고 추가된 매개변수만을 파인튜닝함. ->경제적 절약)
RAG모델
- 등장 배경
- LLM의 정보 제한성( 정보 부족으로 인해 제한된 답변 능력을 보임)과 환각문제(모델이 자신이 모르는 정보를 지어내어 이야기)
- 정보를 데이터베이스에 저장하고, 필요한 정보를 검색하여 LLM에 전달하는 방식으로 구현
- LLM에 미리 질문과 관련된 참고자료를 제공하여 사용하는 방식이기 때문에 보다 신뢰성있는 답변 생성.
- 데이터 처리 과정
- 원본 데이터를 청크 단위의 작은 조각으로 나누기
- 임베딩
임베딩
- 컴퓨터가 단어를 숫자로 표현하여 컴퓨터가 작업할 수 있도록 하는 기술.
- 작동 방식 -Word2vec, GloVe, fasText, ELMo, TF-IDF
프롬프트(Prompt) : ChatGPT에서 대화 시에 하는 질문이나 요청.
'딥러닝(, 머신러닝)' 카테고리의 다른 글
| 컴퓨터 비전 기본 (1) | 2024.02.26 |
|---|---|
| CNN (합성곱 신경망) (0) | 2024.02.19 |
| 경사하강법과 최적화 알고리즘 (2) | 2024.02.05 |
| 시계열 예측 모델, LSTM (1) | 2024.01.29 |
| 샘플링, 데이터 불균형 처리에 대해서 (0) | 2024.01.21 |



