@학연생 발표한 내용을 정리해봐야겠다.
시계열 데이터의 특징
주식 가격이나 날씨 정보와 같이 시간의 경과에 따라서 얻어진 관측치 또는 통계치를 의미한다.
->시간 의존성, 주기성 및 계절성, 다양한 변수 를 시계열 데이터의 특징이라 볼 수 있다.
RNN
LSTM은 순환신경망(RNN)에서 발전된 형태이기 때문에 RNN부터 알아보자.
- 인공신경망의 한 종류로, 입력과 출력 사이에 순환하는 구조를 가진다.
- 시계열 데이터를 처리하기에 좋은 네트워크 구조이며 시간별로 같은 weight를 공유한다.
- 이전의 정보를 기억하거나 활용할 수 있다.

그림에 대한 이해를 돕기 위해 날씨로 예시를 들어본다면?
- 입력 부분 - 기온, 습도, 강수량 등 날씨와 관련된 특성
- 은닉층 부분 - 이전 시간의 날씨 정보를 기반으로 현재 시간의 날씨 변화를 예측한다.
- 출력 부분 - 각 시간 단계에서의 모델의 예측값이 나온다.
RNN 작동 원리
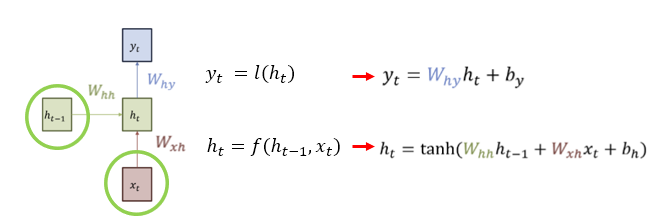
h는 이전 시간의 h 와 x에 영향을 받기 때문에 다음과 같은 함수 식을 세울 수 있다.
y도 마찬가지로 현재 h에 영향을 받기에 다음과 같은 함수 식을 세울 수가 있다.
즉, 현재 상태의 h는 이전의 값들이 누적되기 때문에
이전까지의 상태와, 이전까지의 입력을 대표할 수 있는 압축본이라고 할 수 있다.
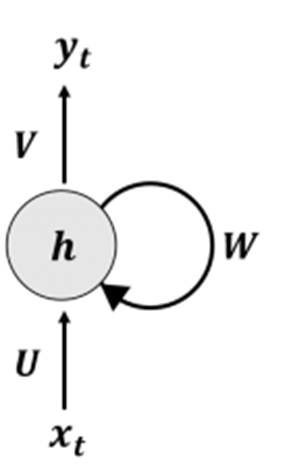
이 그림을 다시 살펴보며 정리해보면.....
•반복적인 학습 간 입력받았었던 과거 데이터를 기억해 현재 데이터와 함께 고려하며, 현재 시간 t시점의 RNN 출력값에 t-1시점의 RNN 출력값이 영향을 주는 피드백 구조.
- t시점의 상태를 t-1의 상태로 저장하여 피드백 하기 때문에 과거 데이터의 은닉층에는 과거의 상태가 누적되어 반영.
RNN의 한계 및 LSTM의 등장 배경
RNN은 W가 반복해서 곱해지기 때문에....
- 곱해진 값이 1보다 크다면
- 문제 : 무한대로 발산해 학습이 더이상 불가능.
- 해결 : 상한과 하한을 정해두는 gradient clipping (근본적인 해결은 아님)
- 곱해진 값이 1보다 작다면
- 문제 : 0으로 수렴하기에 학습의 진행 정도를 파악하기 어려움(기울기 소실문). 학습이 종료된건지, 0으로 수렴한건지 알 수 없음.
- 해결 : 다른 네트워크 구조를 제안. ex) LSTM, GRU
RNN은 단기적인 시간 단위에는 높은 예측성을 보이지만, 중장기 단위의 시계열 자료를 사용한 예측에는 예측률이 낮아지는 양상을 보인다.
LSTM은 '일정한 메모리를 기억하거나 잊어버리는 과정을 통해' RNN의 이러한 기울기 소실 문제를 해결한다.
LSTM

- RNN과 입력, 상태, 출력 구조는 동일 + gate구조
- 셀 스테이트에 존재하는 게이트 레이어를 통해서 내부 네트워크의 데이터를 전달받아 정제하여 데이터를 갱신하거나 삭제하는 기능을 수행
- 입력 게이트 레이어와 출력 게이트 레이어의 도입으로 과거의 값이 필요할 때만 입출력을 할 수 있도록 함
- 망각 게이트를 도입하여 과거의 값 일부를 제거
LSTM의 정보처리 과정
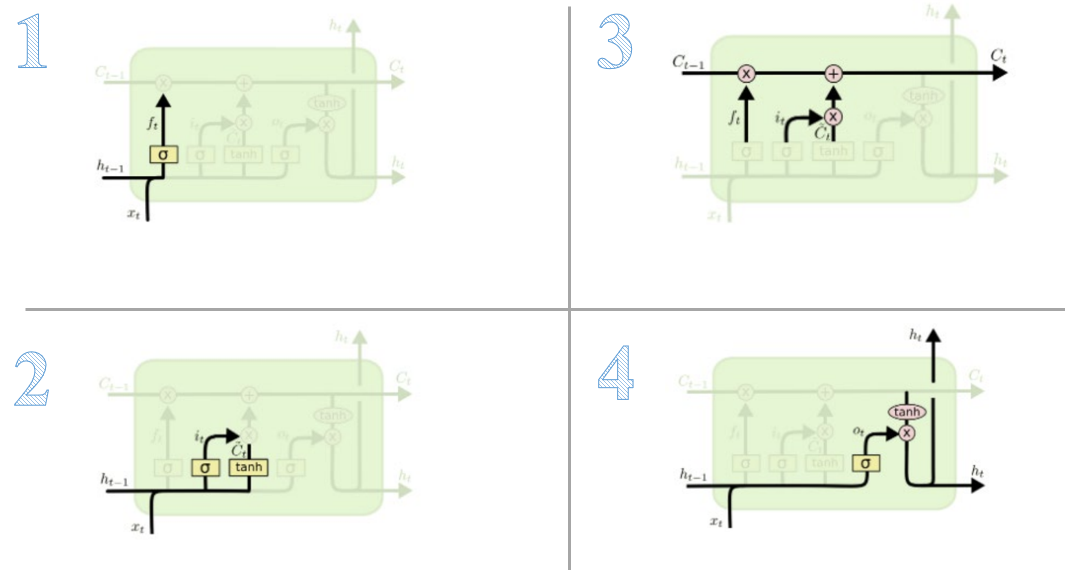
- Forget gate layer 기존의 정보를 얼마나 버릴지를 결정
- Input gate 새로운 정보 중 cell state에 저장할 정보결정
- 1 & 2단계에서 버리기로 했던 정보와 받아들이기로 한 새로운 정보를 Cell State에 실제 Update (1단계와 2단계를 적절히 섞는다고 보면 된)
- Sigmoid값을 통해 현재 cell state를 다음 hidden state로 얼마나 보낼 지를 결정 (정보들을 모두 종합해서 다음 상태를 결정한다고 보면 된다.)
이러한 과정을 수행하며 LSTM은 잊어버릴 것은 빨리 잊어버리고 기억할 것은 오래 기억하게 된다.
LSTM은 시계열 데이터의 장기 의존성을 잘 다루기 때문에, 긴 기간 동안의 데이터를 통해 일정 시간 후의 상황을 예측하는데 효과적이다.
'딥러닝(, 머신러닝)' 카테고리의 다른 글
| 컴퓨터 비전 기본 (1) | 2024.02.26 |
|---|---|
| CNN (합성곱 신경망) (0) | 2024.02.19 |
| LLM모델 (0) | 2024.02.09 |
| 경사하강법과 최적화 알고리즘 (2) | 2024.02.05 |
| 샘플링, 데이터 불균형 처리에 대해서 (0) | 2024.01.21 |



