@센터 입지선정을 위한 데이터 증감법
데이터 불균형 처리
데이터가 불균형한 분포를 가지는 경우, 모델의 학습이 제대로 이루어지지 않을 확률이 높다.
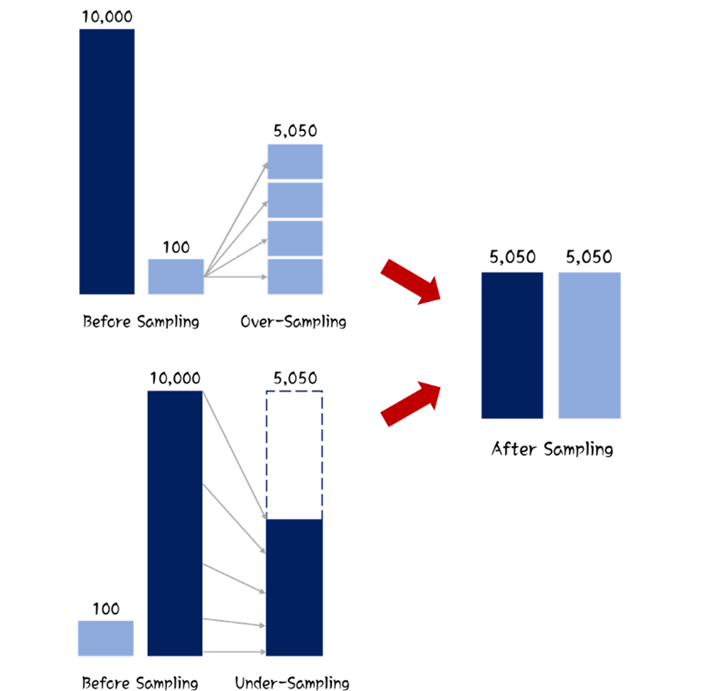
<오버샘플링>
: 낮은 비율 클래스의 데이터 수를 늘림으로써 데이터 불균형을 해소.
- 방법 - SMOTE: 낮은 비율 클래스 데이터들의 최근접 이웃을 이용하여 새로운 데이터를 생성(KNN 알고리즘의 거리 계수를 활용하여 다수와 소수 데이터의 영향 범위를 결정 후 분포 특성을 재구)
- 단점 - 과적합의 가능성 있음. 성능 평가 및 튜닝 과정에서 조심스럽게 사용
- 이용 사례
- [SMOTE와 분류 기법을 활용한 산사태 위험 지역 결정 방법, 2023.06,한국지반공학회] 8가지 데이터를 기반으로 조사->특정 범위에서의 낮은 정확도 ->극복을 위해 SMOTE알고리즘 적용 ->정확도 250%증가. //데이터 개수를 향상시켜 분류 알고리즘의 정확도가 개선
<복합샘플링>
: 오버샘플링과 언더샘플링의 두 기법을 조합하여 사용.
- 방법
- SMOTETomek : SMOTE로 오버샘플링 수행 후(샘플 생성), Tomek link를 사용하여 서로 다른 클래스 간에 가까이 위치한 이상치 샘플을 제거(중복을 제거하는 효과)
- CNN의 변형된 방법. 서로다른 두 표본 i, j에 대해서 i, j보다 더 가까운 표본이 존재하지 않는다면
- SMOTETomek : SMOTE로 오버샘플링 수행 후(샘플 생성), Tomek link를 사용하여 서로 다른 클래스 간에 가까이 위치한 이상치 샘플을 제거(중복을 제거하는 효과)

-
- 중복 제거 : 학습 속도 향상, 과적합 원인 제거. 모델의 일반화 성능 향상
- SMOTEENN : SMOTE로 오버샘플링 수행 후, ENN를 사용하여 이상치나 잘못된 레이블을 가진 이웃을 제거해 모델의 일반화 성능 향상시킴(노이즈 제거하는 방법)
- ENN : CNN의 변형된 방법으로, 집합에 포함된 값이 틀린 분류를 하면 이를 제외시킴. 이진분류만 가능함.
- 노이즈 제거 : 데이터셋에 포함된 부정확하거나 불필요한 정보를 제거하는 것. 이상치, 잘못된 레이블, 이상한 패턴 등을 탐지하고 제거
- 둘다 이진분류만 가능함. (이진분류 : 두 개의 클래스 중 하나로 데이터를 분류하는 문제. 대표적으로 '양성'과 '음성'클래스를 구분 )
-
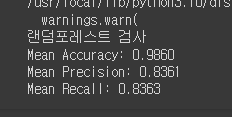
! 랜덤포레스트 모델을 이용해서 SMOTEENN을 돌려봤어요
from imblearn.pipeline import Pipeline
from sklearn.ensemble import RandomForestClassifier
from imblearn.combine import SMOTEENN
from imblearn.under_sampling import EditedNearestNeighbours
from sklearn.model_selection import cross_validate, RepeatedStratifiedKFold
import numpy as np
# Define model (Random Forest)
model = RandomForestClassifier(random_state=42)
# Define SMOTE-ENN
resample = SMOTEENN(enn=EditedNearestNeighbours(sampling_strategy='all'))
# Define pipeline using imblearn's Pipeline
pipeline = Pipeline(steps=[('r', resample), ('m', model)])
# Define evaluation procedure (here we use Repeated Stratified K-Fold CV)
cv = RepeatedStratifiedKFold(n_splits=50, n_repeats=7, random_state=1)
# Evaluate model
scoring = ['accuracy', 'precision_macro', 'recall_macro']
scores = cross_validate(pipeline, X, Y, scoring=scoring, cv=cv, n_jobs=-1, error_score='raise')
# Summarize performance
print('랜덤포레스트 검사')
print('Mean Accuracy: %.4f' % np.mean(scores['test_accuracy']))
print('Mean Precision: %.4f' % np.mean(scores['test_precision_macro']))
print('Mean Recall: %.4f' % np.mean(scores['test_recall_macro']))
[[[참고한 자료
https://towardsdatascience.com/imbalanced-classification-in-python-smote-enn-method-db5db06b8d50
Imbalanced Classification in Python: SMOTE-ENN Method
There are many methods to overcome imbalanced datasets in classification modeling by oversampling the minority class or undersampling the majority class. To increase the model performance even…
towardsdatascience.com
그런데 궁금한 점이 생겼다

AutoEncoder와 Semi-supervised learning(SSL)은 뭘까? 다음에 알아봐야겠다
'딥러닝(, 머신러닝)' 카테고리의 다른 글
| 컴퓨터 비전 기본 (1) | 2024.02.26 |
|---|---|
| CNN (합성곱 신경망) (0) | 2024.02.19 |
| LLM모델 (0) | 2024.02.09 |
| 경사하강법과 최적화 알고리즘 (2) | 2024.02.05 |
| 시계열 예측 모델, LSTM (1) | 2024.01.29 |



